YouTube Categories
This is a post to cover the basics of the YouTube-8M challenge
Contents
Challenge Details
Kaggle hosted the 3rd YouTube-8M Video understanding challenge. Many companies have an interest in things like labeling videos with meta-information such as events happening in a video

An example of the detected action "blowing out candles"
The obvious reason a company has interest in this is to determine video contents that are not described by the uploader. The overall goal of the Yt8M competition is to temporally localize topics of interest.
Data
While several youtube based datasets exist, I will be using the 237k Human-verified 5 second clips (here). This dataset contains 1,000 classes (which were selected to be temporally localizable). Each class is a knowledge graph entity (analogous to a wordnet ID), and each segment is broken into 5 frame-like data points.
Briefly, each frame-like data-point contains audio-visual features for 1 second of the clip. For the visual features, the videos are subsampled to 1-frame/second which was fed into an Inception-V3 network trained on imagenet. This created a 2048 dimensional feature vector per second of video. This was then followed by PCA, and then quantization (1 byte per coefficient). The audio features were extracted using a CNN model over dense spectrograms following Hershey et. al.. Spectrums were calculated at 10ms intervals and converted to log transformed 64 bin mel-spaced frequency bins. These spectrograms are then fed into a CNN and the embeddings are extracted and quantized into 128 8-bit features.
Task
There are a few important notes for what the task is. Specifically, the task is that given a class we predict the relevant segments (and not the other way around!). The specific metric used to evaluate the task is Mean Average Precision @ K where K=100,000. This metric is a bit tricky to understand (and even harder to implement), but I will skip over the details here except for mentioning that compared to global average precision, this metric favors correctly classifying rare events.
The validation training set for the challenge contains 237,667 clips from 47,059 unique videos. The task is to provide 100,000 examples of each class in decreasing order of confidence from a collection of > 2,000,000 clips.
Simple Model
By and large, I took advantage of work other people have made available. I wanted to deconstruct the code for a very simple PyTorch model that placed 21st in the competition1. The model was constructed as follows:
nn.AdaptiveAvgPool1d(1) # average in time dimension
nn.Linear(1152, 2765)
nn.BatchNorm1d(width)
SwishActivation()
nn.Linear(2765, 1662)
nn.BatchNorm1d(width)
SwishActivation()
nn.Linear(1662, 1000)
Swish Activation
Just as a brief note, while ReLU is the most commonly used activation function in machine vision, and many alternatives have been proposed, none have gained common acceptance. The google brain team has proposed a new activation named Swish which is
\[f(x) = x \cdot sigmoid(x)\]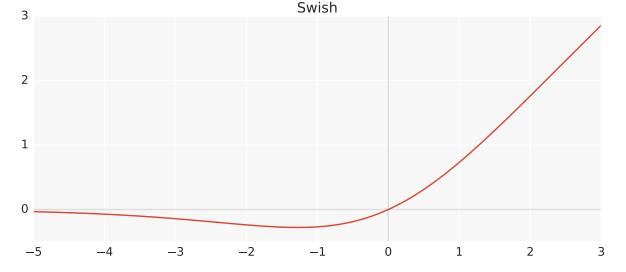
Swish activation from initial paper
Their experiments show improved performance in deep networks (>40 layers) 2
Performance
The publicly available script trains 10 models each on 1/10 of data and then the final submission simply averages the predictions of the 10 models on the test set. While ensembles tend to perform well, they are necessarily difficult to explain/understand. However, in order to verify that a neuronal pool design can be as effective, I ran the public script with a new design.

This network consists of 3,152 neurons. There are 7 update cycles "ticks" for each input prior to reading the output
With this design, since there is a sense of the temporal order of information, I feed each frame in one by one (meaning that the second frame cannot be processed at same time as first frame). This means that steps cannot be readily parallelized and training takes quite a bit longer). While it might be reasonable to simply pool over the inputs, I thought that would be a better discussion for later. Here, there are 7 total updates prior to the read from the output layer.
While we are not interested in having a particularly high score, a reasonable score seems necessary in order to ensure the model is capable of learning/representing the information of interest. As such, the first step was to see how well an ensemble of 6 of the above models performed on the leaderboards. This took approximately 5 hours to train.
results
Closing
The YouTube-8m challenge provides a large dataset that can be used to explore the nature of category representation in ANN’s.